JavaLite ActiveJDBC For ORM In Spark Java
Posted By: Todd Sharp on 4/7/2017 9:19 GMT
Tagged: ActiveJDBC, Groovy, Java, JavaLite, Spark Java

I've spent a lot of time on the blog lately talking about views in Spark Java applications. Rightfully so, as Views are the Turkey in any MVC sandwich (look at it...it's right there in the middle!!). Spark Java provides the crusty Controller slice of bread via routes in our Bootstrap class. So the only thing left is to take a look at the other slice of bread - the Model.

Instead of going with most Java developer's first instinct, Hibernate (for the record, I'm a huge fan), I decided to find a lightweight alternative. Spark Java is all about lightweight, so I found it only fitting to dip my toes into the pool and find something other than Hibernate. Enter ActiveJDBC from JavaLite.
I've only just begun looking at it, but it was pretty easy to get started with my Spark Java application. Step 1, as usual, is to declare our dependencies:ActiveJDBC uses 'instrumentation' to manipulate our POJO domain classes (POGOs in my case) to make things like Domain.where() possible. Those familiar with GORM may know that Grails uses metaprogramming to do this - but with ActiveJDBC it's accomplished with instrumentation. The Gradle instrumentation plugin (added to build.gradle with apply plugin: 'org.javalite.activejdbc') handles this automatically for us, so include that plugin and pretend like you don't even know it's happening during your builds.
I've chosen to use MySQL, so I've created a schema locally called sparkplayground. Next step is to jump over to our Bootstrap class, inside the main() method, to do a bit of configuration. Spark Java gives us a before() and after() methods to perform actions... honestly...is there any way to finish this sentence without being redundant? So, we need to establish our DB connection. In my simple example, I'll open the connection in the before() method and close it in the after(), passing credentials inline - but typical applications will handle credentials via a property file (see documentation). Here's how those look:
Now how about a domain class that ActiveJDBC will recognize:
Why no properties? Well, ActiveJDBC infers DB schema parameters from a database. This means you do not have to provide it in code. At first that bothered me. It still kinda bothers me, but, it is what it is. It does mean that our DB columns dictate our property names on the class. Also, there's no direct access to the properties via getters (or implicit getters in the case of Groovy). You can, however, use wrappers (which seems like a perfect use case for missing method metaprogramming in Groovy - but that's another blog post perhaps). I don't think it's a deal breaker for me, just a new paradigm to live with if I chose to move forward with using ActiveJDBC. And what would programming be without differing APIs between all the frameworks we use?
Anyhow, here's the DDL statement that I used to create the table:Now that our domain is modeled, let's look at some CRUD and retrieval. I created a new route for the application called /javalite.
To persist a new User I create a new instance of the User domain class and populate it. I could use the put(property, value) method, but I prefer passing a map to the fromMap() method. After I save the user with the saveIt() method, I retrieve a list of users with User.findAll(). This gets us a List of User objects. For ease of use in my model, I collect{} that list (triggering the query to execute), grabbing the 'attributes' to get a List of Maps containing all the User properties. Once into the view, I dump the result into a table:
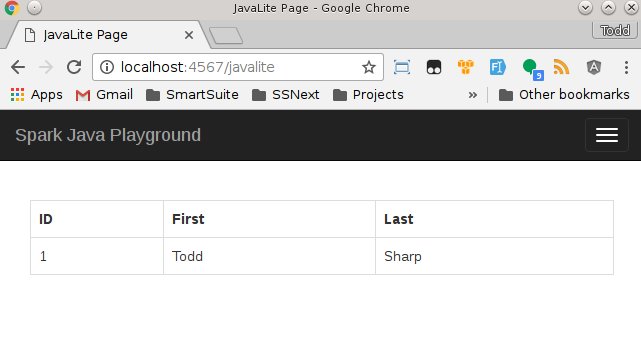
And that's basic CRUD and retrieval with ActiveJDBC in a Spark Java application.
To summarize - there are a few things that seem odd from someone used to working with Hibernate. There is no concept of sessions like with Hibernate, so queries aren't run until the data is accessed. All the usual ORM features seem to be there. Validation, pagination, relationships, transactions, polymorphic associations - all available. It's a framework worth a further look.
Image by JillWellington from Pixabay
Related Posts

Querying Autonomous Database from an Oracle Function (The Quick, Easy & Completely Secure Way)
I've written many blog posts about connecting to an Autonomous DB instance in the past. Best practices evolve as tools, services, and frameworks become...

Sending Email With OCI Email Delivery From Micronaut
Email delivery is a critical function of most web applications in the world today. I've managed an email server in the past - and trust me - it's not fun...

Brain to the Cloud - Part III - Examining the Relationship Between Brain Activity and Video Game Performance
In my last post, we looked at the technical aspects of my Brain to the Cloud project including much of the code that was used to collect and analyze the...