MongoDB via Morphia in Spark Java
Posted By: Todd Sharp on 4/7/2017 2:05 GMT
Tagged: Groovy, Java, MongoDB, Morphia, Spark Java

The latest journey in my quest to see just how many new technologies and frameworks I can learn in one week involves Morphia. Morphia is a "Java Object Document Mapper for MongoDB". In other words, it let's us map our POJOs and POGOs to MongoDB Documents and persist them in MongoDB.
Right, so, on to the codes. To get started with Morphia declare a dependency as such:
compile group: 'org.mongodb.morphia', name: 'morphia', version: '1.3.1'Obviously you'll need to make sure you've got access to a running instance of MongoDB before you try to connect/persist to it. Next, create a domain class - we'll call this one
Person:We've annotated this domain class with @Entity and the ID with @Id as required by the framework. To make things a bit more realistic, I've wrapped some common functionality for dealing with a Person in a PersonService. The service will handle getting a reference to the framework and the datastore (I'd probably include that in an abstract service in a real application) and has a save(), list() and findById() method. Standard stuff:
Next we'll create a simple route in Spark Java to interact with our PersonService, create and persist a new Person if necessary and return a list of Persons to our view.
And finally, the view code if you're dying to see that:
Which results in the following:
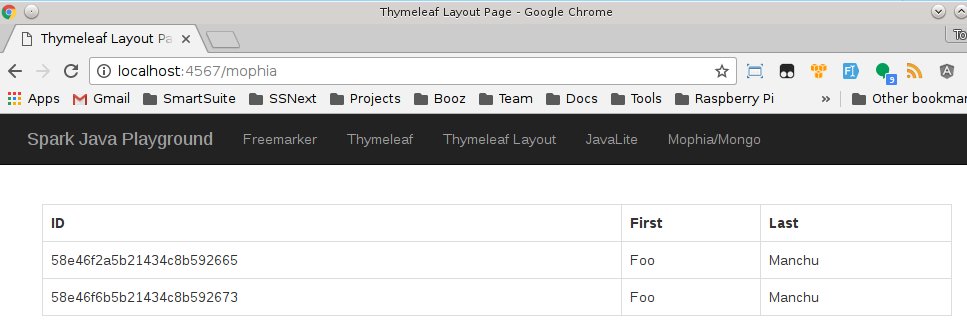
And that's simple object based persistence in MongoDB via a Spark Java application.
Related Posts

Querying Autonomous Database from an Oracle Function (The Quick, Easy & Completely Secure Way)
I've written many blog posts about connecting to an Autonomous DB instance in the past. Best practices evolve as tools, services, and frameworks become...

Sending Email With OCI Email Delivery From Micronaut
Email delivery is a critical function of most web applications in the world today. I've managed an email server in the past - and trust me - it's not fun...

Brain to the Cloud - Part III - Examining the Relationship Between Brain Activity and Video Game Performance
In my last post, we looked at the technical aspects of my Brain to the Cloud project including much of the code that was used to collect and analyze the...