Publishing To Object Storage From Oracle Streaming Service
Posted By: Todd Sharp on 12/23/2019 1:00 GMT
Tagged: Cloud, Containers, Microservices, APIs

In my last post about Oracle Streaming Service (OSS) we looked at how to use the Kafka Connect compatibility feature of OSS to publish changes from an Autonomous DB instance directly to a stream. In this post, I want to show you something as equally awesome: how to write the contents of your stream directly to an Object Storage (OS) bucket. The process will look slightly similar to the process we used in the last post, but there are some notable changes. This time we're going to utilize the Kafka Connect S3 Sink Connector to achieve the desired results. Since Oracle Object Storage has a fully compatible S3 endpoint we can utilize this connector to easily get our stream data into our OCI bucket. The tutorial below will give you all the info you need to make things work, so let's get started.
Preparing For The S3 Sink Connector
User Setup
Before we get started, it would be a good idea to create a project directory somewhere on your machine to store some of the miscellaneous bits and bytes that we'll be working with. We'll refer to that directory as /projects/object-storage-demo from here on out - just make sure to substitute your own path as necessary.
You'll need a dedicated user with an auth token, a secret key and the proper policies in place. To do this, follow the steps outlined in this post. Once you have your user created we'll enhance that user further as outlined below.
Generate Secret Key
The streams user will need a "secret key" created. This will give you an "access key" and "secret key" that we'll use for the S3 compatible credentials that the Kafka S3 Sink Connector requires. In the user details page for your user, click 'Customer Secret Keys' in the sidebar menu and then click 'Generate Secret Key':
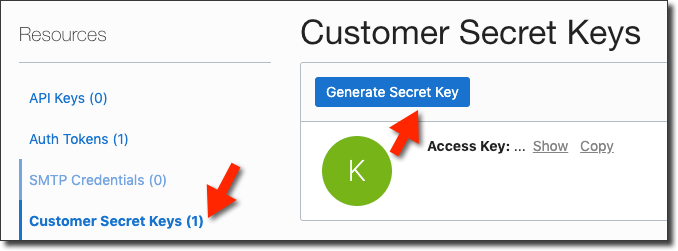
Name your key and click 'Generate Secret Key'.
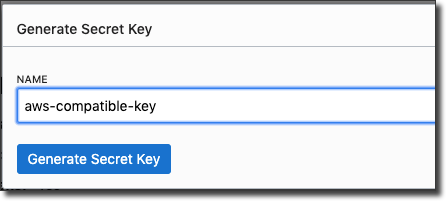
Copy the generated key. This is your AWS compatible 'secret key' value. Save this for later use.
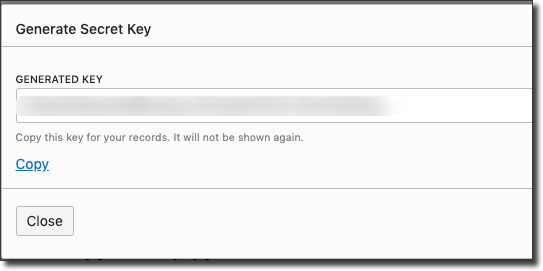
Click Close, then copy the 'Access Key' value. Save this as well.
Before we move on, create a file at /projects/object-storage-demo/aws_credentials and populate it as such:
Modify Policy
Next, modify the policy that you created earlier for this user to make sure it has access to Object Storage. Add two policies like so:
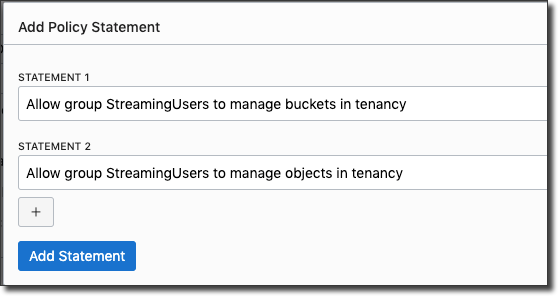
Download Dependencies
We'll need to grab the S3 connector, so download it from Confluent and unzip it so that it resides in your directory at /projects/object-storage-demo/confluentinc-kafka-connect-s3-5.3.2.
Preparing Oracle Streaming Assets
We're going to need a Stream Pool, Stream and Connect Configuration. We'll create each of these below, so head over to the console burger menu and select 'Analytics' -> 'Streaming'.
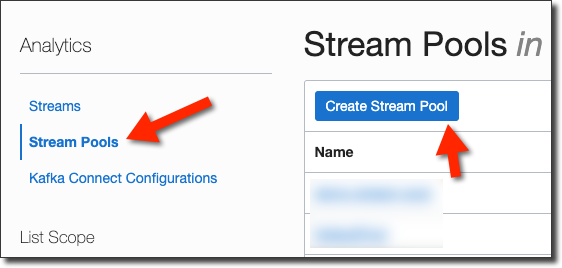
Create Stream Pool And Stream
From the Streaming page, select 'Stream Pools' and click 'Create Stream Pool'.
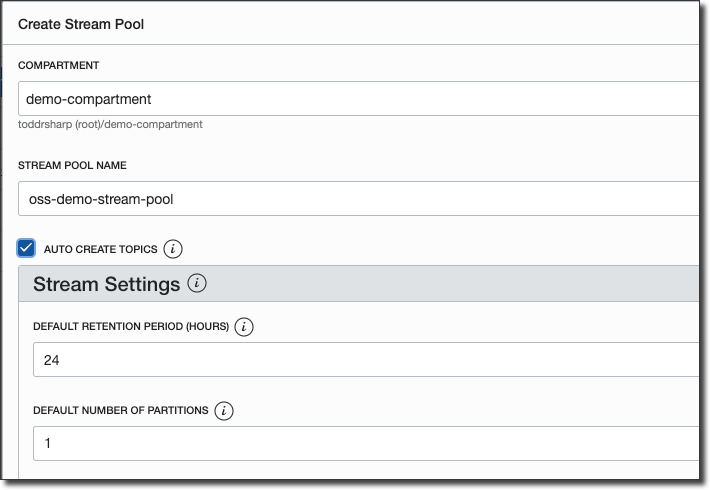
Name the Stream Pool and click 'Create Stream Pool'.
Once the Stream Pool is active, copy the Stream Pool OCID and keep it saved locally for later use. Next, click the 'View Kafka Connection Settings' button.
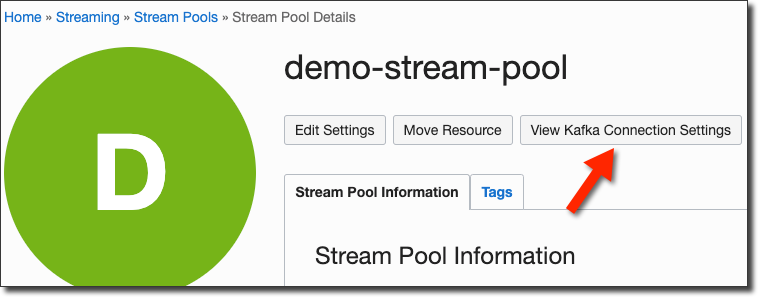
Copy the value from bootstrap server. We'll need this later.
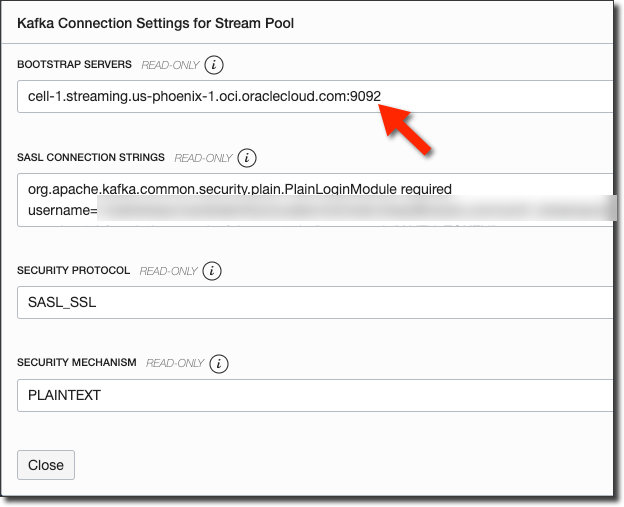
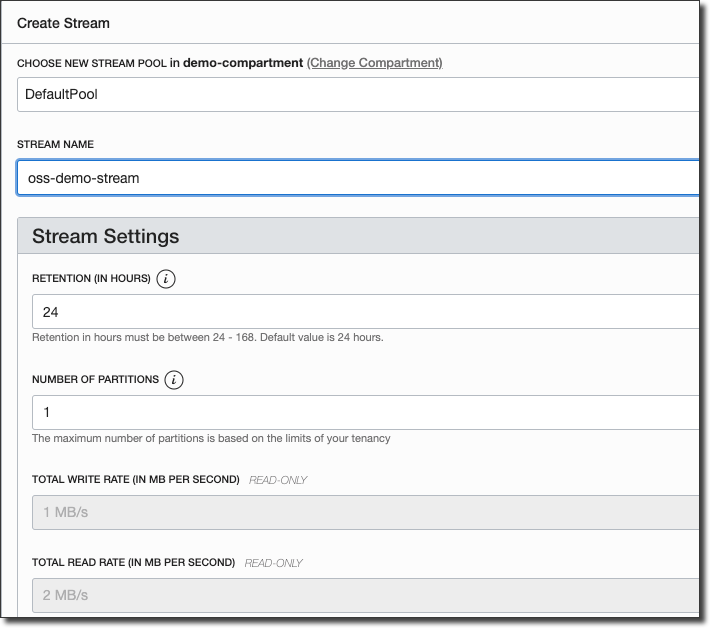
From the Stream Pool details page, click 'Create Stream'.

Name the Stream and click 'Create Stream'. Keep the name handy for later use.
Create Connect Configuration
Now click on 'Kafka Connect Configurations' in the sidebar menu and 'Create Kafka Connect Configuration'.
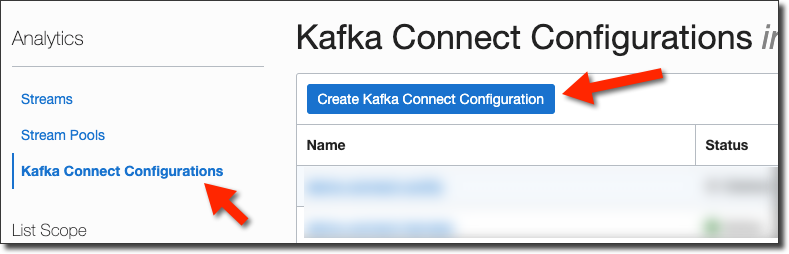
Name the configuration and click 'Create Kafka Connect Configuration'.
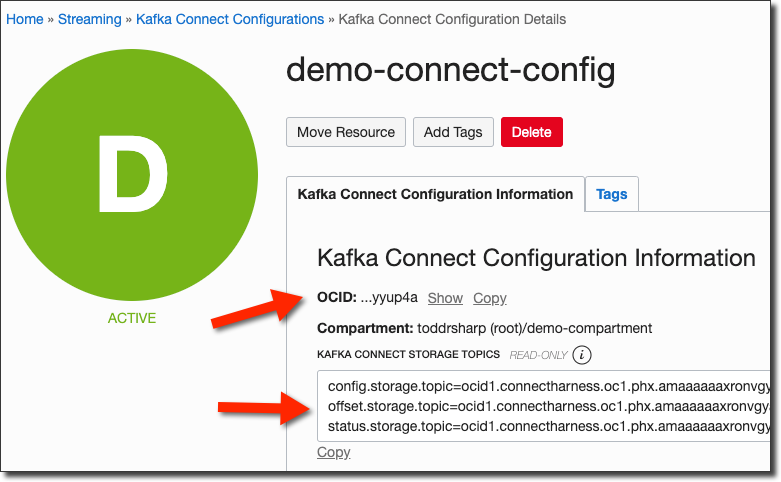
From the Connect Config details page, copy the OCID of the Connect Config.
Preparing Object Storage
We'll need to create a bucket that will ultimately contain our messages. Head over to Object Storage via the burger menu.
Click 'Create Bucket' and name your bucket and create it.
We're now ready to move on to configuring and launching Kafka Connect.
Configuring And Launching Kafka Connect
We're now ready to launch Kafka Connect and create our S3 Sink Connector publish messages to Object Storage. We're going to use the Debezium Connect Docker image to keep things simple and containerized, but you can certainly use the official Kafka Connect Docker image or the binary version. Before we can launch the Docker image, we'll need to set up a property file that will be used to configure Connect. We'll need some of the values that we collected earlier, so keep those handy. We'll also need our streaming username and our auth token.
Create a file called /projects/object-storage-demo/connect-distributed.properties and populate it as such, substituting your actual values wherever you see <bracketed> values.
Set an environment variable in your shell for the connect configuration OCID we collected above:
Now run the Docker image with:
Once Kafka Connect is up and running we can create a JSON config file to describe our connector. Create a file at /projects/object-storage-demo/connector-config.json and populate as such:
Update the topic, s3.bucket.name and store.url as appropriate (you may need to change the region in the URL and s3.region value). If you want more than a single message to end up in the generated file written to Object Storage, update flush.size as appropriate. Refer to the S3 Sink documentation for further customizations.
Now we can POST our config to the REST API to create the source connector:
To list all connectors, perform a GET request:
To delete a connector, perform a DELETE request:
Testing The Integration
At this point we're ready to test things out. You can head over to the stream details page in the OCI console and click 'Produce Test Message' to post a few messages as JSON strings to the topic.
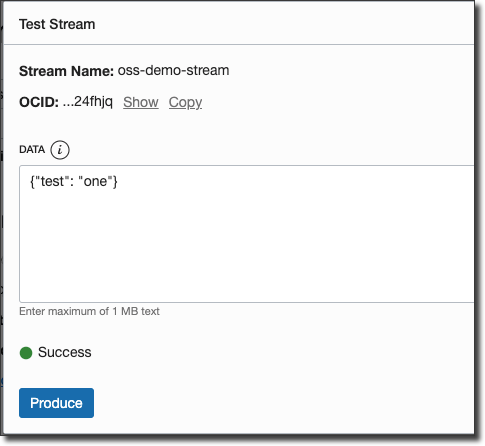
You'll notice some action in the Connect Docker console:
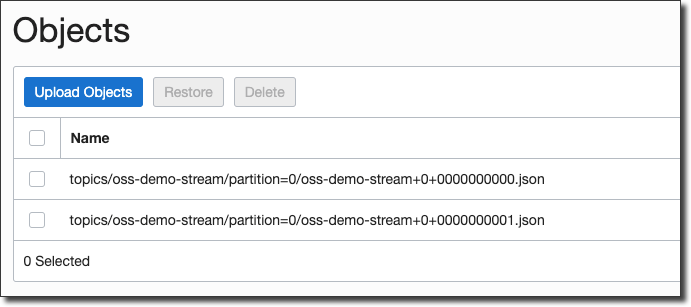
Head over to your bucket to see the files written:
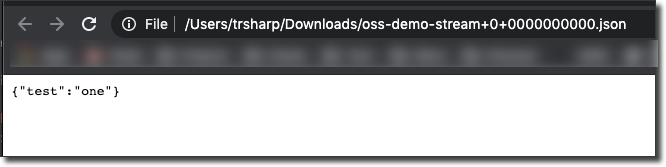
Create a "Pre-Authenticated Request" to download the file and view its contents.
Summary
In this post we created and configured a Stream Pool, Stream and Connect Configuration and used those assets to publish messages from that stream to an Object Storage bucket as files.
Photo by Mathyas Kurmann on Unsplash
Related Posts

Querying Autonomous Database from an Oracle Function (The Quick, Easy & Completely Secure Way)
I've written many blog posts about connecting to an Autonomous DB instance in the past. Best practices evolve as tools, services, and frameworks become...

Brain to the Cloud - Part III - Examining the Relationship Between Brain Activity and Video Game Performance
In my last post, we looked at the technical aspects of my Brain to the Cloud project including much of the code that was used to collect and analyze the...

Brain to the Cloud - Part II - How I Uploaded My Brain to the Cloud
In my last post, we went over the inspiration, objectives, and architecture for my Brain to the Cloud project. In this post, we'll look in-depth at the...