Adventures in CI/CD [#7]: Testing The Persistence Tier With Testcontainers
Posted By: Todd Sharp on 5/11/2020 12:00 GMT
Tagged: Cloud, Containers, Microservices, APIs, Integration, Java, Open Source

Great to have you back for another existing episode in our saga about the joys of cloud deployments with CI/CD. So far, here’s what we’ve gone over:
- Adventures In CI/CD [#1]: Intro & Getting Started With GitHub Actions
- Adventures in CI/CD [#2]: Building & Publishing A JAR
- Adventures in CI/CD [#3]: Running Tests & Publishing Test Reports
- Adventures in CI/CD [#4]: Deploying A Microservice To The Oracle Cloud With GitHub Actions [OCI CLI Edition]
- Adventures in CI/CD [#5]: Deploying A Microservice To The Oracle Cloud With GitHub Actions [Gradle Plugin Edition]
- Adventures in CI/CD [#6]: Adding A Persistence Tier To Our Microservice
Now that we’ve got a functional persistence tier in place, the next step is to update our workflow to deploy the application and any new dependencies to production, right? No, of course not!! We haven’t yet written the necessary tests to ensure a bug-free production build, so of course, we’ll focus on that in this post today. But, since our CI/CD pipeline executes on GitHub's “runner” VM's how can we test our persistence tier? Well, we could spin up an additional “test” database instance, but that could become costly over time and might become difficult to manage. The good news is that there’s a better solution in the form of Testcontainers. Let me borrow a bit of text from their homepage to explain what Testcontainers is:
Testcontainers is a Java library that supports JUnit tests, providing lightweight, throwaway instances of common databases, Selenium web browsers, or anything else that can run in a Docker container. Testcontainers make the following kinds of tests easier: Data access layer integration tests: use a containerized instance of a MySQL, PostgreSQL or Oracle database to test your data access layer code for complete compatibility, but without requiring complex setup on developers' machines and safe in the knowledge that your tests will always start with a known DB state.
How absolutely perfect and helpful is that?! With Testcontainers we can spin up a full Oracle XE database that lives for the life of our tests and allows us to test our microservice the same Oracle DB that it’ll end up being deployed to when it reaches production. This will avoid any potential false positive (and false negatives) that may arise from testing against something like H2 instead of the same engine we’re deploying to in production. OK, if you’re not as excited to dig into the fun as I am yet than I’m not sure we can be friends (or I may just be kinda weird - and that’s certainly a possibility).
Adding Dependencies
We’re going to need to grab the bits and bytes from Maven if we want to use Testcontainers to spin up an Oracle DB instance and make sure that our persistence operations work as we expect them to before we move them to production. Let’s get the Testcontainers Spock JAR and the JAR necessary to work with Oracle-XE DB:
Modifying Our Abstract Spec
If you remember back in part 3 of this saga we created an AbstractSpec class that our other tests would extend. The reason we created that was so when we got to this step we’d be ready to simply modify that base test to create our OracleContainer and initialize that container with the proper configuration so that our tests had an instance of Oracle XE in a Docker container up and running to query against. Let’s make those modifications now.
Take note that we’re passing a path in the OracleContainer constructor to a valid Oracle XE Docker Image that I’ve hosted in my OCIR Docker Registry (phx.ocir.io/toddrsharp/oracle-db/oracle/database:18.4.0-xe). You can use this image in your own tests if you’d like, as it’s a public repo with open access. Also, note the variables we’re passing such as the ORACLE_PWD and some timeout parameters to the test container. Then in the static block, we start the container and our ApplicationContext, passing the configuration for our datasource for the tests. Now we can create tests that test out persistence activities and ensure that they’ll properly execute in our test environment. Why is this awesome? Well, for starters, it means we don’t have to turn up and pay for (and maintain) a “test” database environment just to run our tests against. Also, because we’re using a container that’s running Oracle DB we are able to test against the same system that we’ll ultimately be deploying against in production (instead of testing against an in-memory H2 DB for example that may or may not have full compatibility with our prod DB). Testing against our repo is simple. Let’s add a UserRepoSpec that grabs our UserRepository bean, persists a new user and then queries the DB to retrieve that user.
Running The Pipeline Tests With Testcontainers
That’s all the changes that we need to make to use Testcontainers in our project. We can run our tests locally to confirm and then push our changes to GitHub and watch our pipeline job utilize the new testing infrastructure.
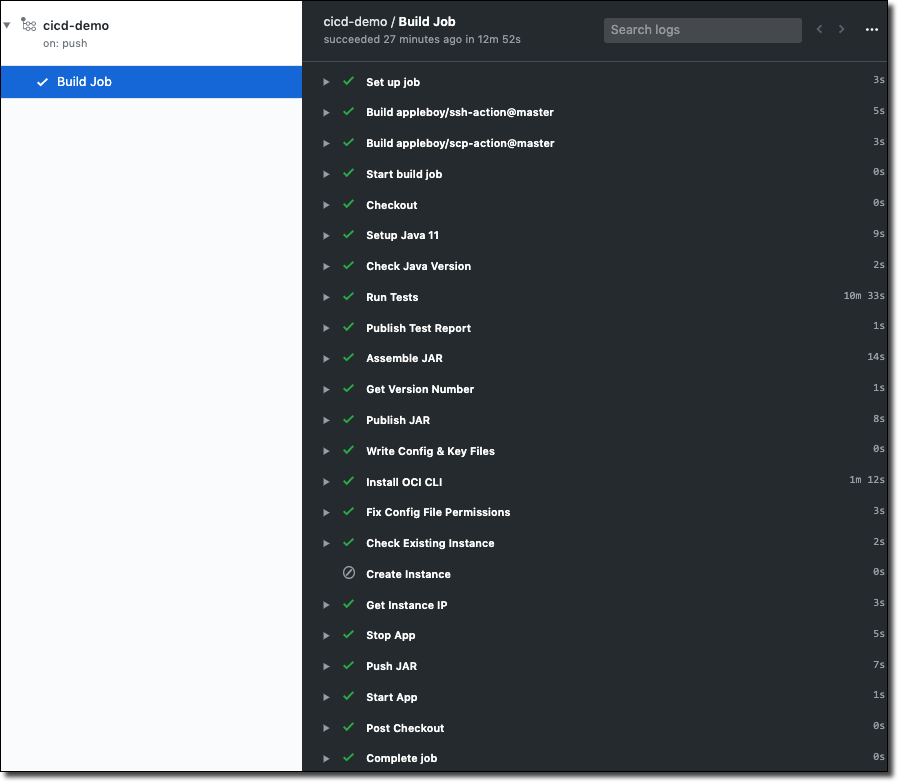
As we can clearly see, the job completed without errors, but it did take a bit longer than it did before. Specifically, the “Run Tests” step took a lot longer than it did before:
If you think about it, this makes sense. Testcontainers needs to pull the Docker Image from my Registry and then build and run the container. That means that the container needs to download and configure Oracle DB in the process, which does take a little bit of time!
We’re trading monetary cost, unreliable results and maintenance complexity for simplicity and reliability all for the price of 10 minutes time. I’d say that’s a fair trade.
At this point, if you were to test the deployed application you would notice that the app is not running. A quick look at the log files on the server would indicate that we’ve yet to configure the proper datasource connectivity for our “production” instance. But that’s another post, so we’ll solve that issue next time!
TL;DR
In this post, we added support for Testcontainers to our microservice application, wrote the proper tests to ensure our persistence tier was bug-free and added the necessary support to our pipeline to execute the new tests.
Next
Next, we’ll update our pipeline to deploy our fully tested microservice with a shiny, new persistence tier.
Source Code
For this post can be found at https://github.com/recursivecodes/cicd-demo/tree/part-7
Photo by Rubén Bagüés on Unsplash
Related Posts

Querying Autonomous Database from an Oracle Function (The Quick, Easy & Completely Secure Way)
I've written many blog posts about connecting to an Autonomous DB instance in the past. Best practices evolve as tools, services, and frameworks become...

Sending Email With OCI Email Delivery From Micronaut
Email delivery is a critical function of most web applications in the world today. I've managed an email server in the past - and trust me - it's not fun...

Brain to the Cloud - Part III - Examining the Relationship Between Brain Activity and Video Game Performance
In my last post, we looked at the technical aspects of my Brain to the Cloud project including much of the code that was used to collect and analyze the...